

How to Secure Generative AI Under the EU AI Act: Compliance, Risk Management, and Best Practices
February 8, 2025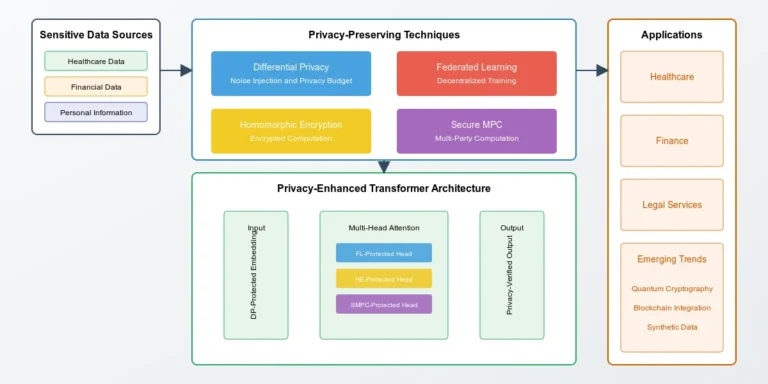
Introduction
In an era where artificial intelligence is no longer the stuff of science fiction but a transformative force reshaping industries, generative AI and Large Language Models (LLMs) like ChatGPT, Gemini Advanced, and Llama stand at the forefront of this revolution. These models have demonstrated an uncanny ability to generate human-like text, create realistic images, and solve complex problems across various domains. From drafting emails and writing code to diagnosing diseases and predicting financial trends, their applications are as vast as they are groundbreaking.
However, with great power comes great responsibility. The capabilities that make these AI systems so potent also introduce significant privacy concerns. As these models become more integrated into our daily lives, they interact with and process vast amounts of sensitive data — ranging from personal healthcare records to confidential financial information. The potential for data leaks, unauthorized access, and malicious attacks not only threatens individual privacy but also poses ethical and regulatory challenges on a global scale.
The Double-Edged Sword of Generative AI
Generative AI is undeniably a game-changer. Its ability to learn from vast datasets and generate new content has opened doors to innovations previously thought impossible. Yet, this very strength can also be a weakness. The mechanisms that allow AI models to learn and generate data can inadvertently compromise privacy.
Key Vulnerabilities:
- Data Memorization: AI models are trained on extensive datasets, and sometimes, they can inadvertently memorize and reproduce sensitive information embedded within that data. This means that during interactions, these models might disclose personal details, proprietary information, or confidential records.
- Membership Inference Attacks: Malicious actors can exploit models to determine whether specific data points were included in the training dataset. This can be particularly damaging when the mere inclusion of data is sensitive — such as an individual’s medical diagnosis or membership in a confidential group.
- Model Inversion: Attackers can reverse-engineer outputs to reconstruct private input data. Essentially, they can infer the characteristics of the training data by observing the model’s behavior, potentially extracting sensitive information.
Real-World Implications:
- Healthcare: A language model trained on medical records might inadvertently reveal patient information when generating responses.
- Finance: A generative model used by a bank could expose transaction details or account information.
- Personal Data: LLMs have been shown to occasionally produce snippets of personal data they were trained on, raising concerns about data protection and privacy.
Key Techniques for Privacy Preservation
To address these challenges, researchers and practitioners are developing and implementing a range of privacy-preserving techniques. These methods aim to protect sensitive data without significantly compromising the performance and utility of AI models.
1. Differential Privacy (DP)
Concept: Differential Privacy adds carefully calibrated noise to data or computations, ensuring that the inclusion or exclusion of a single data point doesn’t significantly affect the output. This makes it difficult to infer information about any individual data point.
Use Cases:
- Google’s RAPPOR: Google’s Randomized Aggregatable Privacy-Preserving Ordinal Response (RAPPOR) system collects aggregate data from users’ browsers without compromising individual privacy. It helps in understanding user behavior while protecting personal data.
- Healthcare Applications: Differentially private synthetic datasets enable researchers to study health trends and disease patterns without exposing actual patient records. For instance, hospitals can share data on COVID-19 cases without revealing individual patient details.
Strengths and Limitations:
- Strengths: Provides strong mathematical guarantees of privacy, widely applicable across different domains.
- Limitations: Introducing noise can reduce the accuracy of the model, especially if not properly calibrated.
2. Federated Learning (FL)
Concept: Federated Learning allows AI models to be trained across multiple decentralized devices or servers holding local data samples, without exchanging them. Instead of sending raw data to a central server, only the model updates (gradients) are shared.
Real-World Examples:
- Healthcare Collaboration: Hospitals across different regions can collaboratively train diagnostic models for diseases like cancer or COVID-19. Each hospital trains the model on its local data and shares updates, improving the global model without sharing patient data.
- Mobile Devices: Companies like Google use FL to improve keyboard suggestions and voice recognition on smartphones by learning from user interactions without sending personal data to the cloud.
Enhancements:
- Privacy-Preserving Federated Learning: Combines FL with techniques like encryption and differential privacy to protect data even during the update-sharing process.
Strengths and Limitations:
- Strengths: Reduces the need for central data storage, and mitigates data transfer risks.
- Limitations: Communication overhead, potential model divergence due to heterogeneous data.
3. Homomorphic Encryption (HE)
Concept: Homomorphic Encryption allows computations to be performed directly on encrypted data without needing to decrypt it first. The results, when decrypted, match the output of operations performed on the plaintext.
Example Applications:
- Banking Sector: Banks can perform fraud detection algorithms on encrypted transaction data, ensuring that sensitive financial details remain confidential throughout the process.
- Cloud Computing: Users can outsource computations to cloud services without revealing their data, as the cloud operates on encrypted information.
Strengths and Limitations:
- Strengths: Provides strong data privacy during computation.
- Limitations: Computationally intensive, leading to slower processing times.
4. Secure Multi-Party Computation (SMPC)
Concept: SMPC allows multiple parties to jointly compute a function over their inputs while keeping those inputs private from each other.
Industry Applications:
- Financial Institutions: Competing banks can collaboratively compute risk models or detect fraud patterns without sharing proprietary customer data.
- Data Analysis: Organizations can jointly analyze datasets (e.g., for market research) without exposing their individual data contributions.
Strengths and Limitations:
- Strengths: Enables collaboration without data sharing, and maintains data confidentiality.
- Limitations: Complex to implement, may involve significant computational overhead.
5. Selective Forgetting
Concept: Also known as “machine unlearning,” this technique allows AI models to “forget” specific data points after training. This is crucial for complying with regulations like the GDPR’s “right to be forgotten,” ensuring individuals can have their data removed from systems upon request.
Implementation Strategies:
- Retraining Models: Removing the data point and retraining the model, although this can be resource-intensive.
- Efficient Unlearning Algorithms: Developing algorithms that adjust the model without full retraining.
Strengths and Limitations:
- Strengths: Enhances compliance with data protection regulations, and builds user trust.
- Limitations: Technical challenges in efficiently removing data influence, and potential impacts on model performance.
Legal and Ethical Dimensions
The intersection of AI with personal data brings it squarely under the purview of legal and ethical scrutiny. Regulations worldwide are evolving to address the unique challenges posed by AI technologies.
Key Legal Considerations:
- Anonymization and De-Identification:
- Challenges: Achieving true anonymization is difficult. Even when data is stripped of direct identifiers, re-identification is possible by cross-referencing with other datasets.
- Regulatory Implications: Laws like the GDPR require data controllers to ensure data is truly anonymized; otherwise, it’s still considered personal data subject to regulation.
2. Right to Be Forgotten:
- Requirements: Individuals have the right to request that their personal data be erased. AI systems must have mechanisms to remove this data not just from storage but also from any models trained on it.
- Technical Challenges: Implementing selective forgetting in AI models can be complex, especially in deep learning models that abstract data representations.
3. Risk Categorization under the EU’s AI Act:
- High-Risk Systems: Applications like biometric identification, critical infrastructure management, and medical devices face stricter requirements.
- Compliance: These systems must adhere to rigorous standards for data governance, transparency, human oversight, and robustness.
Ethical Considerations:
- Transparency: AI systems should be transparent in their operations, allowing users to understand how their data is being used.
- Accountability: Organizations must be accountable for the AI systems they deploy, ensuring they do not cause harm or violate rights.
- Fairness and Non-Discrimination: AI should not perpetuate biases present in training data, which can lead to unfair treatment of individuals or groups.
The privacy-by-design approach emphasizes embedding privacy considerations into the development lifecycle of AI systems from the outset, rather than as an afterthought. This proactive stance is crucial for building systems that are both innovative and compliant.
Emerging Trends and Future Directions
As the field evolves, several trends are shaping the future of privacy in AI.
1. Privacy-Enhancing Technologies (PETs)
Overview: PETs are a suite of technologies that combine methods like differential privacy, homomorphic encryption, and secure multi-party computation to enable secure data handling.
Applications:
- Smart Cities: Managing energy usage, traffic flow, and public safety data without compromising individual privacy.
- Collaborative Research: Universities and institutions can share and analyze data across borders while respecting privacy laws.
2. Synthetic Data Generation
Concept: Generative models like Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs) create synthetic datasets that mirror the statistical properties of real data without containing actual sensitive information.
Benefits:
- Data Sharing: Enables organizations to share data for research and development without exposing personal information.
- Augmenting Datasets: Helps in situations where data is scarce or imbalanced by generating additional samples.
Industries Leveraging Synthetic Data:
- Healthcare: Creating synthetic patient records for developing diagnostic tools.
- Finance: Simulating transaction data to detect fraud patterns.
3. Real-Time Privacy Audits
Concept: Incorporating auditing mechanisms into AI systems to monitor data handling and detect potential privacy breaches in real time.
Features:
- Automated Alerts: Systems can flag unusual data access or potential violations immediately.
- Compliance Checks: Continuous monitoring ensures adherence to policies and regulations.
Advantages:
- Proactive Protection: Identifies and mitigates risks before they lead to breaches.
- Building Trust: Demonstrates a commitment to privacy, enhancing user confidence.
Balancing Innovation and Privacy
While privacy-preserving techniques offer promising solutions, they often come with trade-offs that need careful consideration.
Key Trade-Offs:
- Accuracy vs. Privacy:
- Impact: Techniques like differential privacy introduce noise, which can reduce the accuracy of AI models.
- Considerations: Finding the right balance between data protection and model performance is crucial. This might involve tuning the level of noise or employing hybrid approaches.
2. Scalability:
- Challenges: Methods like homomorphic encryption and secure multi-party computation can be computationally intensive, making them difficult to scale for large datasets or real-time applications.
- Solutions: Ongoing research is focused on optimizing these algorithms and leveraging hardware accelerations.
3. Complexity:
- Integration: Combining multiple privacy techniques can increase system complexity, requiring specialized expertise.
- Maintenance: Complex systems can be harder to maintain and update, potentially introducing new vulnerabilities.
The Path Forward:
Innovations in AI must go hand in hand with advancements in privacy protection. Collaborative efforts between researchers, industry practitioners, policymakers, and ethicists are essential to navigate these challenges. By fostering a multidisciplinary approach, we can develop powerful AI systems that respect individual rights.
Conclusion
Generative AI and Large Language Models hold immense potential to drive innovation across various sectors. However, their success hinges on the ability to earn and maintain public trust. Privacy is not just a technical or regulatory box to check — it’s a fundamental human right and a societal imperative.
By embracing privacy-preserving technologies, adhering to ethical principles, and committing to transparency and accountability, we can ensure that AI serves humanity without compromising individual freedoms. As explored in our papers, safeguarding sensitive data is a complex challenge, but it’s one we must tackle head-on.
Together, we can build a future where AI is not only a tool for advancement but also a guardian of our values and rights.
Future Directions
The evolution of Generative AI and Large Language Models represents a critical intersection of technological advancement and privacy protection. This review has examined the current landscape of privacy-preserving techniques, regulatory frameworks, and ethical considerations in AI systems. Several key areas warrant further research and development:
Research Priorities:
1. Optimization of privacy-preserving techniques to reduce computational overhead while maintaining effectiveness
2. Development of more efficient selective forgetting algorithms for large-scale models
3. Integration of privacy-preserving techniques with emerging AI architectures
Industry Implementation:
1. Standardization of privacy-preserving protocols across AI development pipelines
2. Development of industry-specific benchmarks for privacy-preservation in AI systems
3. Creation of comprehensive privacy impact assessment frameworks
For Further Investigation:
– Researchers are encouraged to explore the scalability challenges in implementing privacy-preserving techniques across distributed systems
– Industry practitioners should consider contributing to open-source privacy-preserving AI frameworks
– Policymakers may benefit from examining the real-world impact of current privacy regulations on AI development
Essential Resources for Privacy-Preserving AI
Primary Open-Source Tools
- Privacy-Preserving ML Frameworks
- TensorFlow Privacy (Google) — https://github.com/tensorflow/privacy
- PySyft — https://github.com/OpenMined/PySyft
- CrypTen (Meta) — https://github.com/facebookresearch/CrypTen
- Diffprivlib (IBM) — https://github.com/IBM/differential-privacy-library
2. Implementation Guidelines
- Microsoft’s Privacy-Preserving ML Best Practices
- Google AI’s Privacy Standards
- OpenAI’s Safety & Privacy Guidelines
Academic Venues
- Primary Conferences
- NeurIPS Privacy in ML Track
- ICLR Security & Privacy Sessions
- PETS (Privacy Enhancing Technologies Symposium)
- ICML Privacy-Preserving ML Workshop
2. Specialized Workshops
- PPML Workshop (NeurIPS)
- PPAI Workshop (AAAI)
- PriML Workshop (Multiple Venues)
Key Frameworks
- Technical Standards
- IEEE P2830™ (Shared ML Framework)
- ISO/IEC 27701 (Privacy Information Management)
- NIST Privacy Framework
- NIST AI Risk Management Framework
2. Regulatory Guidelines
- ENISA AI Security Guidelines
- EDPB AI Data Protection Guidelines
Research Organizations
- Industry Labs
- Google AI Privacy Research
- Microsoft Research Privacy Group
- Meta AI Privacy-Preserving ML
- OpenAI Safety & Privacy Team
2. Academic Centers
- OpenMined Research
- MLCommons Privacy Working Group
Community Resources
1. Learning Resources
- Privacy-Preserving AI GitHub Organization
- Kaggle Privacy Competitions
- AIcrowd Privacy Challenges
2. Technical Blogs
- Google AI Blog — Privacy Section
- OpenAI Blog — Safety & Privacy
- Microsoft Research — Privacy in AI
Newsletters & Magazines
- Industry Updates
- IAPP Privacy Tech Newsletter
- IEEE Security & Privacy Magazine
- ML Privacy Digest
Note: Due to the rapid evolution of privacy-preserving AI, readers should:
- Verify the current status of resources before use
- Check for updated versions of frameworks and tools
- Review the latest publications in conference proceedings
- Monitor regulatory changes affecting AI privacy
For the most current information, consider joining relevant professional organizations (IEEE, ACM, IAPP) and following their updates.
As this field evolves rapidly, collaborative efforts between researchers, industry practitioners, and policymakers will be crucial in shaping the future of privacy-preserving AI systems.
- Reach Out: Feel free to connect with me on LinkedIn to discuss these ideas further.
- Stay Informed: Follow me for more articles on AI, privacy, and technology ethics.


